
What Should You Know About Multimodal AI in 2025?
AI vs Automation | AI Automation Tools | Business Process Automation
Wondering what multimodal AI is? Let me explain it in simple words. Imagine asking your AI assistant to find the perfect outfit for your body type using just a picture you upload. It’s incredible how multimodal AI combines visual and textual inputs to deliver personalized recommendations, saving you hours of research. With recent breakthroughs, multimodal AI can understand and respond to any data you provide, whether it’s images, words, or sounds, and then produce outputs in your preferred format.
So, what exactly is multimodal AI? How does it work, what benefits does it bring, and what are its use cases and real-world applications? All of this comes together in one complete guide.
Let’s explore this exciting and transformative technology together!
What is Multimodal AI?
Multimodal AI is a type of artificial intelligence that refers to machine learning models designed to process and integrate information across multiple data formats (modalities) to understand and generate content in a human-like way.
In contrast to traditional AI models, which are generally designed to handle a single type of data, multimodal AI combines and analyzes multiple data modalities, including text, images, audio, video, and other forms of sensory input. Thus, it will achieve a more comprehensive understanding approach and generate more robust outputs.
A multimodal model can get a photo of a corporate room as input and generate the written summary, describing its unique features. A simple example of multimodal AI is Google Lens, which leverages both images and text together. When you drag your phone’s camera into a simple product or at a plant, Google Lens promptly recognizes the image and generates the text that explains to you what the image is about and provides useful information.
Moreover, this AI model can take a written description of that corporate room and generate an image that resembles the room description. It works vice versa and has two-way ability where image to text and text to image were created. A simple example of converting text into images using multimodal AI is OpenAI’s DALL-E. This AI model gets written descriptions like “a futuristic city skyline at sunset”. It then generates creative images that match the description and provide valuable results.
Therefore, Google Lens performs an image-to-text task by recognizing images and creating textual information, while DALL-E gets a textual description and converts it into vivid images.
How Does Multimodal AI Work?
Artificial intelligence is a rapidly evolving field where the latest advances in training algorithms are used to build foundation models for multimodal research. Since the beginning, deep learning frameworks and data mining have become popular. However, now multimodal innovation and development, including audio-visual speech recognition and multimedia content indexing technologies, set the stage for today’s generative AI.
Here is the step-by-step process of how it works:
- Modality-Specific Processing
- Information Fusion
- Unified Output
1. Modality-Specific Processing
The system begins by processing each type of data utilizing specialized models. For instance, it can use a natural language processing (NLP) model to understand the text and a computer vision model to evaluate images.
No matter what type of input the AI gets, whether it’s a word, a pixel from a picture, or a sound, the AI first changes it into a common format it can understand. This common format is called vectors, which are simply sets of numbers. By turning all the different types of data into numbers, the AI can compare, combine, and process them more easily; as a result, it can understand the full picture much more effectively.
2. Information Fusion
Next, the AI merges the insights from these different models. This step is where the AI learns to recognize patterns between different data types. For example, it can link the words “golden retriever” in text with an image of that dog breed. This is similar to how a recommendation system correlates user preferences across multiple inputs.
3. Unified Output
Finally, the AI produces a single, clear result. This might be answering a complicated question, describing a video, or creating new content based on the combined inputs. Because it uses multiple data sources together, multimodal AI can deliver more complete and accurate results than systems that only use one kind of data.
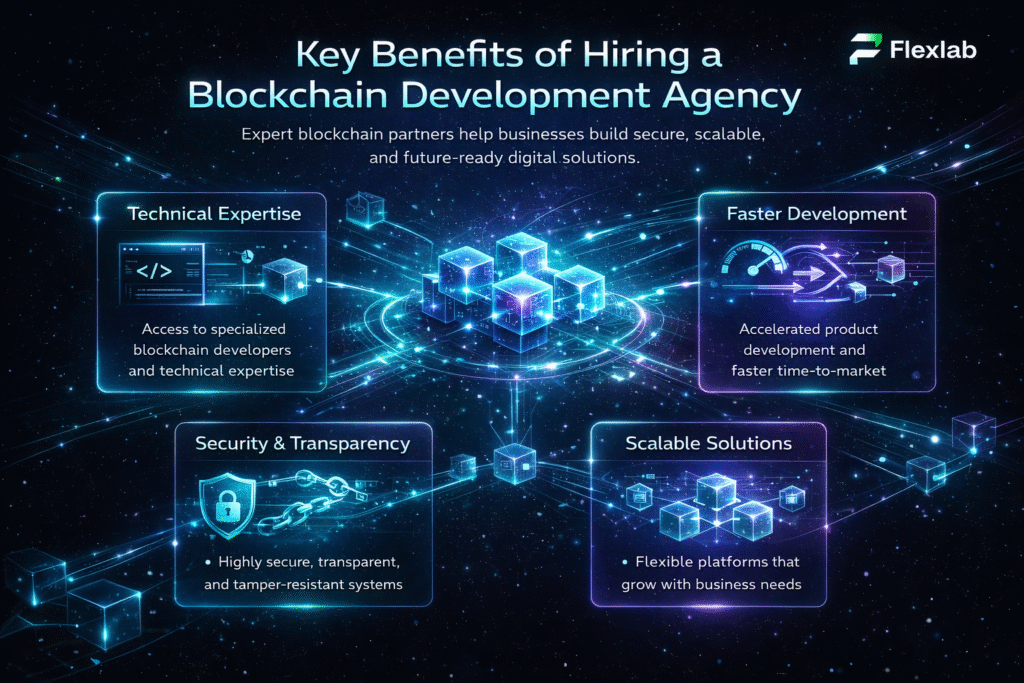
Benefits of Multimodal AI

There are several benefits of multimodal AI that perform versatile tasks compared to unimodal AI. Here are some key benefits:
- Better Contextual Awareness & Understanding
- Cross-Domain Learning
- Improved Creativity & Problem-Solving Skills
- More Accurate Outputs
- More Intuitive User Experience
Better Contextual Awareness & Understanding
Multimodal AI combines information from different sources like text, images, audio, and video, allowing it to get a richer and more complete understanding of a situation. For example, if you show it a picture of a broken laptop and tell it “It won’t turn on,” the AI can process both the image and your words together to help figure out the problem more effectively.
Cross-Domain Learning
Multimodal AI not only handles various data types but also learns connections between them. It understands how emotions are expressed in speech and text, as well as how they appear visually. This makes it useful in areas like mental health support and personalized education by recognizing tone of voice and facial expressions simultaneously, important in sentiment analysis applications.
Improved Creativity & Problem-Solving
Because it can blend different types of data, multimodal AI opens up new creative possibilities. It can generate captions for images, create content from video or audio, and solve complex problems by thinking through data more like a human would.
More Accurate Outputs
Access to multiple kinds of data lets multimodal AI cross-check and confirm its understanding. For instance, when a healthcare assistant analyzes patient notes, examines X-rays, and listens to symptoms described by voice, it can provide more accurate diagnoses and recommendations. As a result, it works much like today’s AI chatbots in healthcare, yet with far greater depth and reliability.
More Intuitive User Experience
Multimodal AI understands many ways people communicate; it works with voice commands, typed questions, or photos. This natural interaction makes using AI easier and more accessible, especially for people who prefer speaking or using images instead of typing.
Top 6 Examples of Multimodal AI Models
- CLIP: Contrastive Language-Image Pre-training (CLIP) is a multimodal vision-language AI model by OpenAI that executes image classification tasks. It matches descriptions from contextual datasets with corresponding images to generate relevant images without requiring specialized training for each task.
- DALL-E: It is a generative AI model by OpenAI that produces images based on text prompts with the help of frameworks like GPT-3. This AI model takes unrelated ideas and creates a brand-new image that involves objects, animals, and text.
- LLaVA: The Large Language and Vision Assistant (LLaVA) is an AI model that can understand pictures and text together. As a result, it helps humans obtain detailed explanations or descriptions of what they see in an image.
- CogVLM: Cognitive Visual Language Model (CogVLM) mixes language and vision understanding, allowing machines to do tasks like answering questions about images or generating related text based on what the picture shows.
- ImageBind: This model is designed to connect multiple types of data, including audio, images, video, and text, within a single framework. Consequently, it helps AI make sense of different sources of information simultaneously.
- GPT-4o: This AI model is an advanced version of OpenAI’s GPT series that handles multiple input types, including text and images, making it capable of understanding and generating content across different forms of media. It also features capabilities that explain how ChatGPT works.
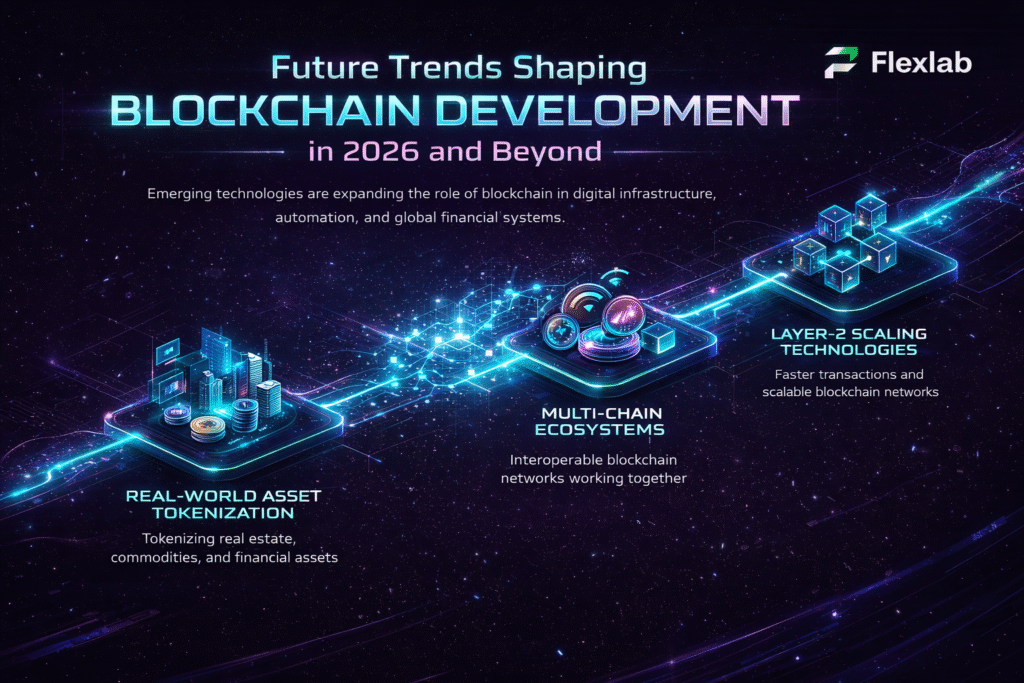
Trends in Multimodal AI 2025
Here are several key trends that are shaping the development of multimodal AI.
- Unified and Advanced Foundation Models
- Better Cross-Model Interaction
- Real-time Multimodal Processing
- Multimodal Data Augmentation
- Open Source and Collaboration
- Integration with AI Agents and Robotics
- Research into Neuro-Symbolic and Hybrid Models
- Text-to-Video Generation
1. Unified and Advanced Foundation Models
Leading multimodal AI models, including OpenAI’s GPT-4o Vision, Google’s Gemini, and other unified models, are designed to combine text, images, audio, and video into a single powerful system. These AI models understand and generate multimodal content smoothly. It makes human-like yet practical content.
2. Better Cross-Modal Interaction
New techniques like advanced attention mechanisms and transformer models help these AI systems better connect and blend data from different formats. As a result, they can create answers and outputs that are more accurate and, moreover, better aligned with the surrounding context.
3. Real-time Multimodal Processing
AI applications are rapidly used in many areas, such as self-driving cars and augmented reality. It must process input from many sensors, such as cameras, LIDAR, microphone, that make a decision instantly. Real-time processing assists these autonomous systems in responding safely and accurately.
4. Multimodal Data Augmentation
To teach AI better, researchers create synthetic data that combines multiple modes, such as pairing text descriptions with images. This augmented data helps AI models learn more effectively and perform better.
5. Open Source and Collaboration
Communities and platforms like Hugging Face and Google AI share open-source multimodal AI tools, which, in turn, make it easier for developers and researchers to work together. Moreover, these shared resources help them exchange ideas and ultimately push the technology forward.
6. Integration with AI Agents and Robotics
Multimodal AI is integrated into autonomous AI agents and robots, enabling them to make decisions and perform tasks by understanding visual, textual, and auditory inputs. This empowers applications like self-driving cars, smart home devices, and industrial robots, demonstrating the importance of ChatGPT integration for business.
7. Research into Neuro-Symbolic and Hybrid Models
By combining deep learning with symbolic reasoning, neuro-symbolic models enhance both logical reasoning and factual accuracy. Consequently, these models are becoming increasingly important in fields such as legal tech, scientific research, and education, as they provide reliable and explainable AI outputs.
8. Text-to-Video Generation
Generative AI is moving beyond images and can now produce videos from text prompts. Moreover, new tools generate narratively coherent, audio-visual content; as a result, they are revolutionizing media and creative industries with fully AI-generated videos.
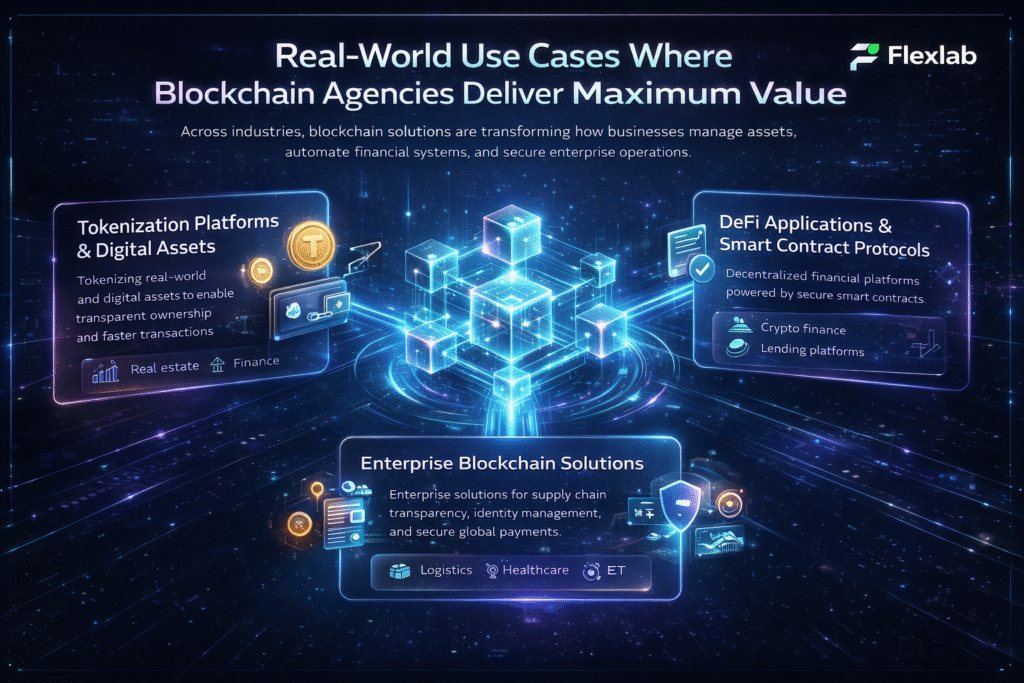
Real-World Applications of Multimodal AI
Multimodal AI is changing the way many industries work by combining and understanding different types of data—like text, images, sounds, and videos—all at once. This makes AI smarter and more useful. Here are some of the most important real-world uses of multimodal AI today:
-
Healthcare Diagnostics
In healthcare, multimodal AI blends MRI and X-ray images, patient history, and live health data to help doctors diagnose diseases faster and more accurately. As a result, it can spot early signs of illnesses, personalize treatments, and, moreover, assist in complex fields such as oncology and radiology.
-
Autonomous Vehicles
Self-driving cars use multimodal AI to combine data from cameras, radar, lidar, and GPS sensors. As a result, they can recognize pedestrians, vehicles, road signs, and obstacles in real time, which in turn makes driving safer and more reliable.
-
Retail and E-Commerce
Multimodal AI helps online stores understand customers better by analyzing their browsing history, product images, and reviews. Consequently, it can recommend products that customers are more likely to enjoy and, moreover, enhance the shopping experience with features such as image-based searches.
-
Security and Surveillance
Smart security systems use multimodal AI to analyze video footage along with audio signals, thereby detecting suspicious activities more quickly. As a result, responses to potential threats are accelerated, which in turn helps maintain safer environments.
-
Manufacturing and Predictive Maintenance
By combining sensor data, visual inspections, and historical equipment records, multimodal AI predicts when machines might fail. This allows companies to schedule maintenance before problems occur, reducing downtime and saving money.
-
Customer Service
Multimodal AI enables better customer support by analyzing voice, text, and facial expressions together. As a result, virtual AI assistants and chatbots can provide more accurate and, moreover, empathetic responses.
-
Education and Accessibility
AI powered by multiple data types helps make learning more inclusive. For example, it can convert speech to text, describe images for the visually impaired, and tailor interactive content to accommodate different learning styles.
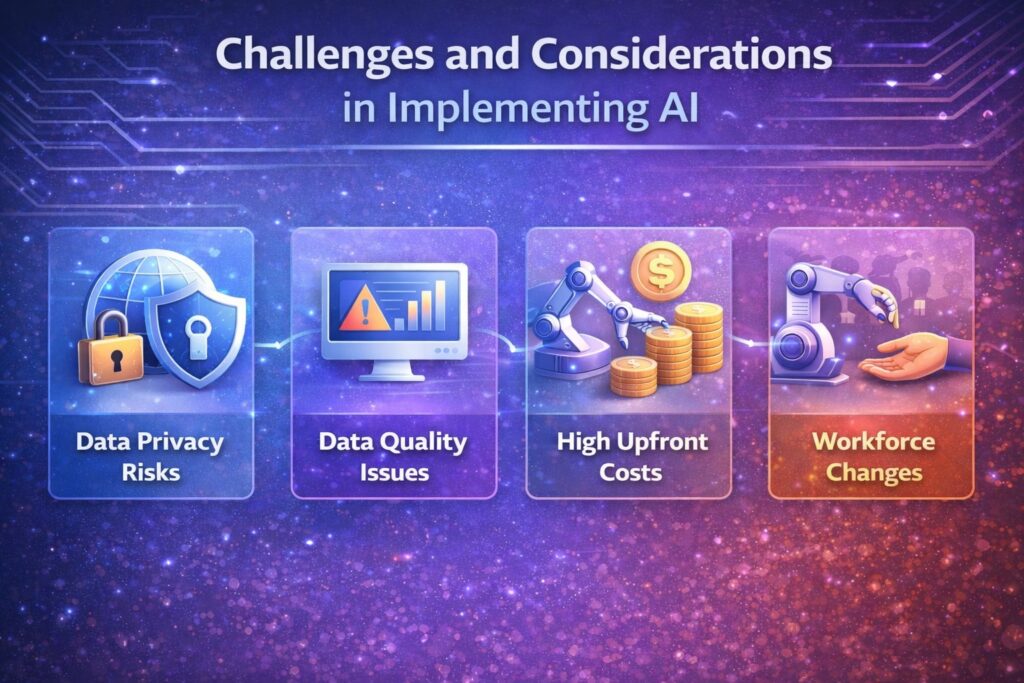
Challenges and Limitations of Multimodal AI
Multimodal AI is powerful but comes with several challenges and limits:
- Data Integration: Combining different types of data, such as text, images, and audio, is challenging because each type comes in a different format and quality. Therefore, ensuring that all this data aligns and works together correctly can be difficult.
- High Cost and Computing Needs: These models need a lot of computing power and memory, which makes them expensive to train and run. This can limit smaller companies or teams from using the technology.
- Training Complexity: Training multimodal AI takes longer and needs more fine-tuning than simpler models. Missing or low-quality data in any modality can cause the AI to make mistakes.
- Generalization Gaps: Sometimes, even if a model performs well on test data, it struggles with real-world situations, especially when subtle reasoning or noisy inputs are involved.
- Bias and Fairness: Multimodal AI can inherit or even amplify biases from training data, leading to unfair or biased results if not carefully managed.
- Interpretability: These models are often “black boxes,” meaning it’s difficult to understand how they make decisions. Consequently, this raises concerns regarding trust and regulation.
- Real-Time Processing: However, handling multiple data streams at once can slow down real-time applications, such as self-driving cars or live translation systems.
The Future Of Multimodal AI
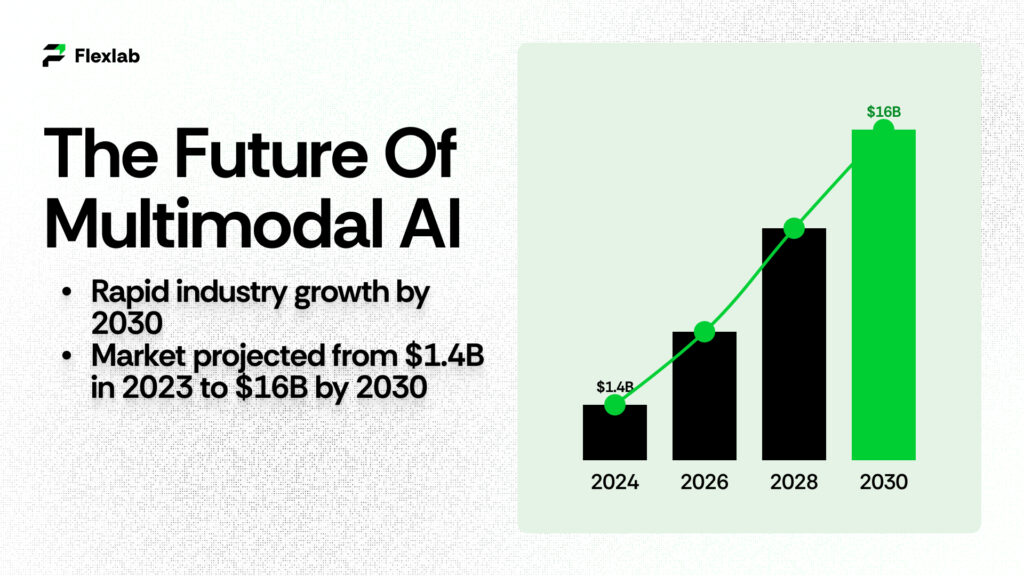
Multimodal AI is rapidly advancing and will play a major role across many industries over the next decade. Experts predict the multimodal AI market will grow from about $1.4 billion in 2023 to nearly $16 billion by 2030, an annual growth rate of over 40%.
This surge is driven by the technology’s ability to understand and combine text, images, audio, and video in one system. As a result, AI becomes smarter and more human-like. Models like OpenAI’s GPT-4 and Google’s Gemini will also improve at handling multiple data types simultaneously. Consequently, AI tools will become even more powerful and easier to use.
How Flexlab Empowers Businesses to Leverage Multimodal AI Models

Flexlab empowers businesses to leverage multimodal AI models by designing, building, and scaling advanced AI solutions that integrate multiple data types, such as text, images, audio, and video, into unified systems. Consequently, this enables companies to gain richer insights, automate complex tasks, and, in turn, make smarter, context-aware decisions across their operations. Flexlab’s expertise includes creating custom multimodal AI pipelines and deploying cutting-edge models that fuse data from various modalities in real time, enhancing applications like personalized customer experiences, intelligent automation, and predictive analytics.
Connect with us on LinkedIn to stay updated on the latest in multimodal AI innovation, business transformation, custom AI agents, use of AI in fraud detection, and cybersecurity risk assessment.
Ready to transform your business with multimodal AI? Contact us today for a personalized consultation and start your AI-powered journey.
📞 Book a FREE Consultation Call: +1 (416) 477-9616
📧 Email us: info@flexlab.io
Closing Remarks About Multimodal AI
In conclusion, multimodal AI is changing how machines understand and interact with the world by combining text, images, audio, and video into one system. This technology allows AI to grasp a fuller picture and provide smarter, more accurate answers. It powers real-world applications from healthcare to autonomous vehicles, enhancing decision-making and user experiences.
Unlock More Insights:
Is ChatGPT multimodal?
Yes, since 2025, ChatGPT has multimodal abilities, meaning it can understand and respond to inputs like text, images, and voice. It can analyze pictures, listen to spoken prompts, and provide voice replies, making interactions more natural and dynamic.
What is the difference between generative AI and multimodal AI?
Generative AI focuses on creating new content like text, images, or audio, usually from a single input type. Multimodal AI, on the other hand, processes multiple data types, such as text, images, audio, and video. As a result, it can generate richer and more context-aware outputs.
What's the difference between Multimodal AI and traditional (unimodal) AI?
Multimodal AI works with many kinds of data at the same time (like text + images), giving it a deeper understanding and the ability to handle complex tasks. Traditional unimodal AI handles just one data type (only text or only images), so it provides more limited insights and capabilities.

























5 Responses
Awesome blog.